為替トレードの不規則な動きを可視化してみた
前回のランダムな結果を受けて
前回の記事では、ランダムネスから為替チャートをおおよそ再現できるか確認した。おおよそ再現できるというのが前回の結果だった。
今回の記事では、実際の為替チャートの統計的ふるまいを可視化することに挑戦してみることにした。
Twitterのフォロワーさんに教えていただいた情報では、ランダムウォーク的にふるまうことがミクロな理論から確認されたらしい。詳しくは以下の記事を参照のこと。
トレードのデータ
約1秒おきの為替チャートのデータ1か月分を以下からダウンロードした。
用いたデータはJPY/USDの8月分。
一定時間でサンプリングして統計を取る
111単位時間分のデータをヒストグラムとして集計し、ガウス分布にフィッティングし、その形の時間変化をアニメーション化したものが次の動画である。

この動画を見るとわかるが、唐突に分散が小さくなったり、平均値の位置が一瞬で飛んだりする。やはり、ほとんど不規則に見える。(うにょうにょしていてかわいい。)量子力学の確率分布の時間発展に似たなにかが現れるかもしれないと0.000001%くらい期待していたが、そんなに甘くはなかった。何か規則性のようなものを読み取れる方がいたら、ぜひ教えていただきたい。
参考までにガウス分布で平均値と標準偏差の乱数を発生させ、そこからガウス分布を再生成した場合のランダムな時間発展の動画も貼っておく。

なんだか実際のチャートの時間発展よりランダムに見える。やはり、実際のチャートは完全なランダムとはなんらかの差があるのだろうか?
一応、平均値と標準偏差の時間変化も貼っておく。

ソースコード
gistd43c90b6b030e3d5d0fb5fc9febfb8dc
まとめ
ランダム的なものは、心惹かれるなーとつくづく思う。
為替レートは乱数で再現可能なのか?について
問題提起
今も昔も為替取引が活発に行われている。しかし、その未来予測は困難とされており、実際ランダムウォークのようであるとも言われている。もし、仮に完全にランダムウォーク的であるならば、分儲けと損がそれぞれ50%の確率で起こり、手数料が引かれる分期待値は必ずマイナスとなるはずである。そこで、今回は日本円と米ドルの為替レートがランダムウォーク的かどうか検証してみることにした。
検証用元データ
検証用データは1日単位で、100日分のデータを以下のサイトから拝借した。
各日にちの最大値と最小値、およびその平均値をプロットすると次の図のようになる。

短期間データの標準偏差
まず各日にちについて、平均値を最大値と最小値から引き、日にちに関する平均と標準偏差を求めた。最大値と最小値で大差はなく、平均からのずれの平均が程度で、標準偏差が
程度であった。
長期間の振る舞いがわかっている状況下での乱数によるずれ
元データの平均値から、平均値、標準偏差
正規分布に従う正規分布を足したり引いたりして、少しだけ短期的な乱数の影響を入れて為替チャートを乱数を用いて再生成したのが次の図である。

この図を見る限り、実際の為替チャートと大きなずれはなく、上昇か下落かを当てる確率は約75%程度となる。
その場合の損益は手数料を2%としてもほとんどの場合黒字になる。
しかし、分布の平均的な長期の振る舞いを事前に知ることは困難なため、この例はあくまで、短期の予想に乱数が入った場合、どれほど影響が出るかを見ているに過ぎない。
長期の平均値の予想も乱数で生成してみた
5日ごとに平均値が変動するとして、正規分布で平均値0で分散が適当な(値により価格の振れ幅が変わる)乱数を生成し
長期的なふるまいをランダムウォーク的に決定し、それに短期間の乱数を加味したものをいくつか生成してみた。


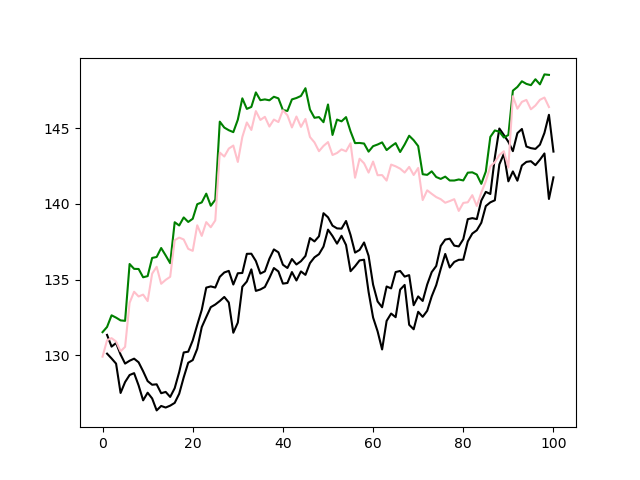


黒の線が現実のチャートで、緑とピンクの線がそれぞれ、乱数によって生成されたチャートである。特に例1は実際の為替チャートと酷似しており、為替チャートがある程度ランダムになりうることを強く示唆している。上昇、下降の当たる確率はおよそ1/2で、期待値はマイナスになる傾向が大きかった。
疑問
いくら乱数で生み出されたチャートが現実のチャートと酷似しているとはいえ、為替の取引を行っているのは人間もしくはアルゴリズムに従ったコンピューターである。そこには、なんらかの意思や傾向が含まれているはずであるのに、なぜ乱数で生成したチャートが実際のチャートと酷似してしまうのか疑問である。ひょっとすると、僕たちの目の錯覚や思い込みで実際により詳細にデータを分析すれば、乱数が生成したチャートと現実のチャートの違いを判定する方法が存在するのかもしれないが今のところ不明である。
一人ひとり異なるとはいえ、戦略をもって行われているはずの、大衆の意思決定の結果がランダムになりうるのか?この疑問を解決するには実際のチャートとランダムなチャートをより詳細に調べる数学的ツールが必要になってくると思われる。
プログラム
今回、検証に用いたプログラムを貼っておく。
局在アンダーソンモデルの臨界点の次元依存性( dimensional dependence of the critical point of the Anderson model with box distribution )の線形フィット
局在アンダーソンモデルの臨界点の次元依存性(dimensional dependence of the critical point of the Anderson model with box distribution)
局在アンダーソンモデルでbox distributionを仮定したときの臨界点が整数次元についてほぼ線形に増加していることに気づいたので、フィッティングの結果をここにメモしておく。僕の先行研究とGarcia-Garciaさんたちの結果を線形フィットしてみた結果が次の図である。

式は、
である。で[W_c=0]となるようにフィッティングし直すと、

で式は、
である。
本来であれば、僕の過去研究(https://journals.jps.jp/doi/abs/10.7566/JPSJ.83.084711)に載せるべき結果であったが、先行研究の6次元のデータをうっかり見落としていて、線形でないように見えていたのが問題であった。
級数の極限値と総和法の関係について
指数関数とパデ近似と極限
指数関数の級数展開での極限を考えてみよう。
……①
パデ近似を用いて、関数列を生成すると、
……②
……③
……④
などが考えらえる。ところが、①式の右辺の極限値を先にとると、級数の次数の増加に関係なく、②の場合は、で明らかに0に収束し、④の場合は、
では明らかに正の無限だいに発散する。
このように、級数の極限値をとるとき、どのような総和法を選択するかによって、値が変わってくるのだ。ちなみに、
となる。言いたいことは、指数関数という無限遠で明らかに発散しそうな関数でさえ、総和法の取り方次第で、極限値がかわってしまうのだ。それどころか多点総和法を用いれば、任意の値に収束させることができてしまう。
僕の今日書いた記事で、
総和法を問題点として提起して留まっているのもここに根本的な理由がある。級数と総和法の「自然な関係」とは一体なんなのだろうか?
SRWS理論を用いて、臨界指数を計算するための新しい道筋(未完)
SRWS理論におけるグリーン関数の級数展開(t>lを仮定)
部分積分を用いれば、二項係数の和の問題をある程度回避できると気づいたのでメモ。
なお、viXraにあげてあるプレプリントで使っていた無限次元近似は、使っても使わなくても厳密に計算した場合と同じ結果を与えることがわかったので報告しておく。
この記事で紹介する方法は、プレプリントのマイナーアップデートである。
積分近似と部分積分
総和公式を積分と合わせて近似する。
これを積分で近似して、
となる。部分積分を用いて、
nに依存する項だけを残すと、
ここで、Φはレルヒの超越関数であり、
次にに関する和
を、となるように総和を取らないといけないが方法は今のところ不明である。
の第一項については、
なので、第一項は無視してよいことが分かる。
追記(2022/09/02):少し進展があった。詳細は以下の記事で。
2次方程式の複素数解とグラフの幾何学的関係
2次関数と2次方程式
2次関数
を考える。2次方程式が実数解を持つとき、その解は、と
の交点で与えられる。
それでは、複素数解を持つときはどうなるだろうか?
幾何学的に考察してみよう。
2次方程式の解の公式
2次方程式が実数解を持たないと仮定すると、
一方のグラフの頂点は、
より、
となる。
さて、このようにして得られたグラフの頂点を、元のグラフの頂点と比べる。すると、x座標は同じで、y座標はいくらかずれている。そして、そのx座標は2次方程式の複素数解の実部に等しく、y座標は2次方程式複素数解の虚部の定数倍に等しい。
このようにして、2次方程式の複素数解と元のグラフとの関係が得られた。
実数解の場合グラフの軸から等距離にx軸方向に等距離にずれた位置の点に解があった。複素数解の場合、グラフの頂点からy軸方向にx軸から上下に等距離ずれた位置の点に対応する解がある。
このように実数解の場合も複素数解の場合も、x軸上のある点から等距離ずれた場所に2つの解に対応する点があることが分かった。
【臨界点の高精度見積もり】局在アンダーソンモデルのζ関数を近似的に試験的に構成してみた
局在アンダーソンモデル(Orthogonal class)
ここで、は互いに独立な確率変数で、
の範囲で一様に分布する。
は最近接の格子点のみにわたる和を表す。
この記事では、次元立方格子を取り扱う。
エネルギー準位統計
アンダーソンモデルのハミルトニアンを対角化して、エネルギーを得る。
各乱数のサンプル事に、エネルギーをとしたとき、そのエネルギー準位の差を
で計算する。ここで、の平均値を
としたとき、
とすると、こののとる値の分布は局在状態で、指数分布、広がった状態で広がった分布、臨界点で系のサイズに依存しない分布が得られる。
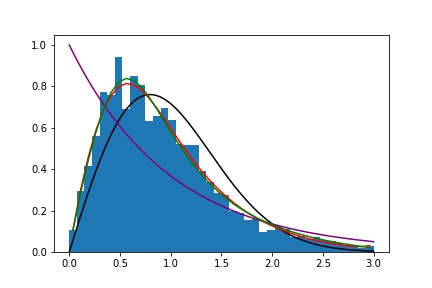
臨界点での分布をパデ近似で近似した関数はで、
ζ関数とオイラー積
得られたエネルギー順位間隔の分布関数から逆に、エネルギー順位間隔を生成する。今回は200個生成した。
このような生成方法を取るので、臨界状態以外は無限系の性質をとらえられていると考えられる。
得られた順位間隔に対して、
とオイラー積を定義する。本当は無限個の項をかけないと意味がないので、テイラー展開とパデ近似を使って、近似してみることにする即ち、
これを展開して、パデ近似する。今回は対角パデ近似を用いた。
そして、得られた近似ζ関数の零点と極を調べてみた。
極は、相の状態に寄らず円形に分布することが分かった。
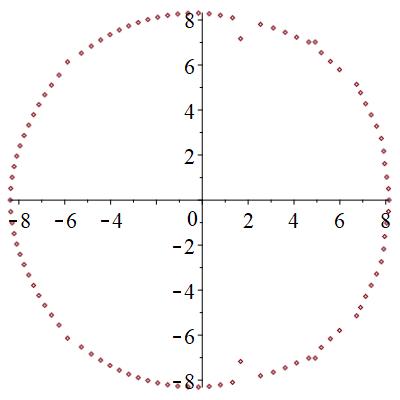
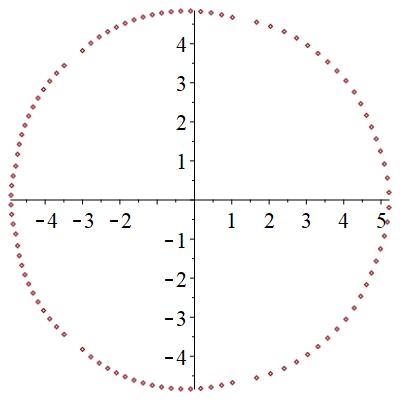
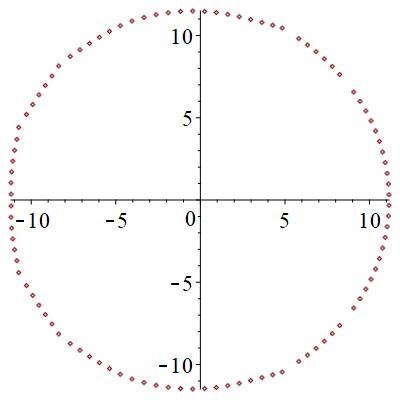
零点は、局在状態では、下図のように、広がった状態では円形に分布するものが見つかる。また、局在状態では2つの領域に分断される。臨界状態では、サンプル事に、局在か広がった状態かの2つの状態になったりならなかったりする。特に、中間的な零点分布を取ることがある。
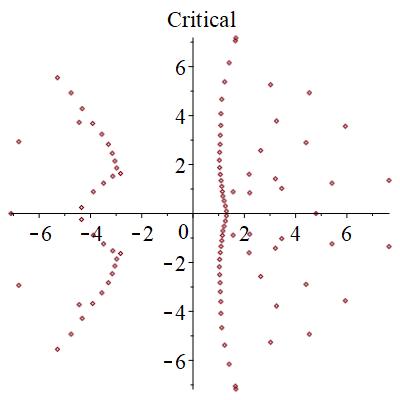
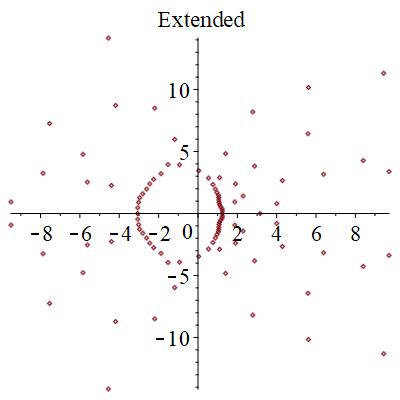
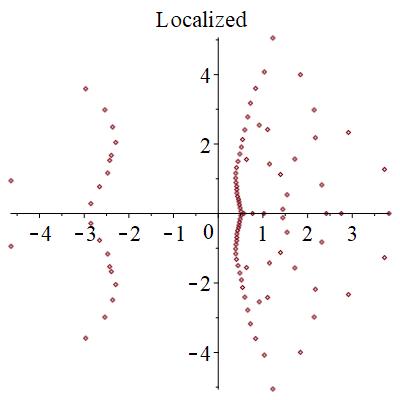
結論
零点のつながり方というトポロジカルな情報をランダムなサンプル毎に見ていくことで、臨界点が程度であることが分かった。このように有効数字4桁~5桁程度の精度で判別できるのがこの手法の強みである。
一方で、この手法の弱みは、つながっているかどうかの判断を人の目で見て判断しているという曖昧さが残っているという点と、サンプル数が十分とれているかという問題がつきまとう点である。しかし、サンプル数をより多く取れば、臨界点のより精度の高い見積もりが可能になると考えられる。